character encoding
- 문자나 기호들의 집합을 컴퓨터에서 표현하는 방법.(UTF8, UTF16)
character set
- 정보를 표현하기 위한 글자들의 집합을 정의한 것. 한 문자 집합을 여러 문자 인코딩에서도 사용가능(ex: 유니코드)
유니코드라는 character set은 각 글자가 특정 bytes에 대응되는 집합을 의미한다. 예를 들어 ‘안’은 유니코드로 “C5 48”이라는 값과 대응되고, ‘녕’은 “B1 55”라는 값에 대응된다.
UTF8과 UTF16은 모두 유니코드라는 character set을 이용한 인코딩 방식을 의미한다.
인코딩은 쉽게 말해 컴퓨터가 이해할 수 있는 byte값으로 변환함을 의미한다. 따라서 ‘안’을 UTF8로 인코딩 한다는 의미는 “C5 48”이라는 값을 규칙에 따라 특정 byte값으로 변환하겠다는 의미이고, 이는 “EC 95 88(안) EB 88 95(녕)”로 변환된다. 비슷하게 ‘안’을 UTF16으로 인코딩하면 “C5 48”이라는 값이 규칙에 따라 “C5 48(안) B1 55(녕)”로 변환되게 된다.
다양한 character encoding 종류
1. EUC-KR
ASCII 영역(127이하)은 그대로 1byte의 동일값을 사용한다. 한글은 주로 2byte로 표현되며 한글 완성형 인코딩이다. 한글 완성형은 ‘가’를 ‘ㄱ’와 ‘ㅏ’로 나누지 않고 ‘가’ 자체가 하나의 byte값에 대응됨을 의미한다. 반대 표현으로는 한글 조합형이 있으며, 현재는 거의 사용되지 않는다.
2. MSWIN949(CP949)
MS사가 도입한 인코딩 방식으로 한글은 주로 2byte로 표현한다. EUC-KR을 확장했기 때문에 하위 호환성이 있다. EUC-KR이 표현할 수 없는 한글 문자도 표현 가능하다.
3. UTF-8
가변길이 유니코드 인코딩(1byte ~ 4byte)으로 ASCII 영역(127이하)은 그대로 1byte의 동일값을 사용한다. 한글은 주로 3byte로 표현한다. 인터넷 사이트에서 가장 많이 쓰이는 인코딩으로 엔디안에 상관없이 똑같이 읽을 수 있다는 장점이 있다. 또한 리눅스나 maxos에서는 운영체제 자체의 인코딩 형식을 UTF-8로 통일했다.(window는 레거시 호환을 위해 UCS-2와 병행)
한글의 경우 UTF-8 완성형/조합형 두가지 형식으로 표현할 수 있다. “안녕”을 완성형(NFC)으로 표현하는 경우 “EC 95 88(안) EB 88 95(녕)”이 되며, 조합형(NFD)으로 표현하는 경우 “E1 84 8B(ㅇ) E1 85 A1(ㅏ) E1 84 82(ㄴ) E1 84 82(ㄴ) E1 85 A7(ㅕ) E1 84 8B(ㅇ)” 이 된다.
Mac os는 키보드 입력을 제외하고는 한글을 조합형으로 저장하고 있다. 이로인해 Mac에서 저장한 파일을 DBMS에서 order by할 경우 무조건 앞에 위치하는 현상이 발생하기도 한다.(조합형 한글의 자음 encoding값이 완성형 한글 encoding값보다 항상 작기 때문에) 현재 DBMS 에는 한글 NFD와 NFC를 동시에 order by하는 기능이 없기때문에 python의 sorted를 이용해야 정상적으로 정렬가능하다.
4. UCS-2 (Universal Character Set)
유니코드 이전에 사용된 국제 인코딩 규격으로 2byte로 이루어져 있다. 총 65,536개의 영역을 사용하고 이 영역을 BMP(기본 다국어 평면)이라고 한다. ASCII 영역(127이하) 문자들도 각각 2byte로 표현되므로 변환없이는 영문자도 호환되지 않는다.
5. UTF-16
가변길이 유니코드 인코딩(2byte, 4byte)으로 2byte영역(BMP영역)까지는 UCS-2와 동일하나, 가변길이 부호화를 통해 4byte영역까지 확장함으로써 더 많은 문자를 표현할 수 있다. ASCII 영역(127이하) 문자들도 각각 2byte로 표현되므로 변환없이는 영문자도 호환되지 않는다.
유니코드란
-
전 세계의 모든 문자를 다루도록 설계된 표준 문자 전산 처리 방식(키와 값이 1:1로 매핑된 형태의 코드)
-
유니코드는 하나의 코드셋으로 모든 문자를 나타내야하고, 가변길이라는 특성때문에 특별한 처리를 거쳐 인코딩되게 된다.
-
EUC-KR과 차이점 : 예를 들어 EUC-KR로 “안녕”을 나타내면 “BE C8(안) B3 E7(녕)”인데 만약 이렇게 인코딩된 파일을 사용자가 실수로 EUC-JP로 디코딩한다면 BE C8 B3 E7에 해당하는 일본어(照括)로 출력이 된다. 하지만 유니코드는 전세계의 모든 문자가 unique한 값을 가지기 때문에 UTF8-KR, UTF8-JP같은 개념이 없고 모든 나라의 문자가 UTF-8로 인코딩/디코딩 될 수 있다.
유니코드 인코딩 방법(아래의 표 참고)
- “안녕” 이라는 한글 문자열이 있을때 유니코드표를 보면 ‘안’=C548, ‘녕’=B155이다.
- “C5 48(안) B1 55(녕)”를 UTF-8로 인코딩하게 되면 000800-00FFFF영역이므로 3+3 = 6byte가 되며 해당 값은 “EC 95 88(안) EB 88 95(녕)” 이다 “C5 48(안) B1 55(녕)”를 UTF-16으로 인코딩하게 되면 000800-00FFFF영역이므로 2+2 = 4byte가 되며 해당 값은 “C5 48(안) B1 55(녕)” 이다

character encoding 과정
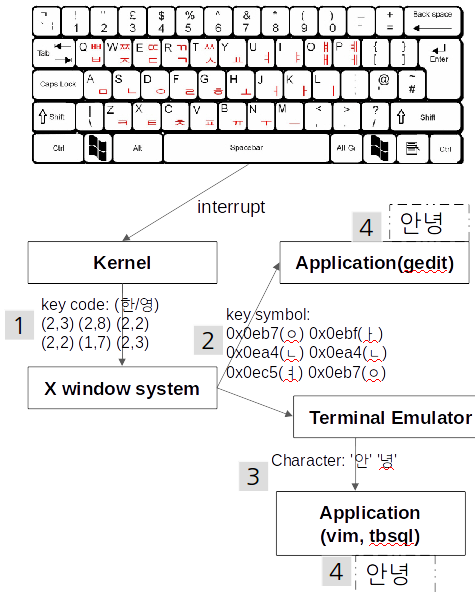
keyboard의 입력부터 terminal에서 출력되기까지 어떤 과정을 거치게 되는지 살펴보자.
우선 keyboard에서 (한/영)키를 눌러서 한글입력으로 전환한 후에 “안녕”을 입력한 상황을 생각해보자.
우리가 ‘ㅇ’, ‘ㅏ’, ‘ㄴ’, ‘ㄴ’, ‘ㅕ’, ‘ㅇ’ 여섯개의 버튼이 눌리면 메인보드, CPU를 거쳐 kernel에 인터럽트가 보내지게 된다.
- 커널은 해당 인터럽트를 키보드상에서의 물리적 위치값(key code)으로 변환해서 X window system으로 보낸다.
- X window system에서는 함께 눌린 modifier key(Ctrl, Shift 등)을 분석해서 key code를 key symbol로 변환한다. key symbol은 ‘ㅅ’,’ㅆ’, ‘A’, ‘Left_alt’와 같은 character형태로 표현되는 symbol을 의미한다. 해당 key symbol은 GUI application이나 terminator로 전달되게 된다.
- terminal emulator에서는 해당 key symbol을 받아 설정된 charset encoding에 맞게 byte값으로 변환하게 된다. 예를 들어 terminal인코딩이 UTF-8이라면 terminator는 “EC 95 88(안) EB 88 95(녕)” 의 6byte로 변환 후 vim이나 tbsql처럼 terminator위에서 동작하는 application으로 전달된다. gedit과같이 terminal과 별도로 동작하는 application은 (3)의 과정이 application내부에서 일어나게 된다.
- application에 encoding된 byte값이 저장된다.
locale, vim과 character encoding
1. 변수 의미 설명
- locale: 사용자의 언어, 국가뿐 아니라 사용자 인터페이스에서 사용자가 선호하는 사항을 지정한 매개 변수의 모임
- LANG: LC_* 환경변수에 대한 default값을 지정. 즉 지정되지 않은 LC_환경변수에 대해서 LANG값이 설정됨. LC_이 설정되면 LANG셋팅을 오버라이딩함.
- LC_ALL: LC_*환경변수 일괄 setting
- terminal encoding: terminal옵션 들어가서 셋팅해주는 charset encoding
- vim의 encoding: vim 자체의 인코딩, 즉 터미널로부터 전달받은 character들을 vim은 자신의 인코딩으로 해석하여 받아들이게 된다.
- vim의 fileencoding: file로 저장할 때 인코딩. 터미널에서 file -Bi file_name해보면 나오는 file의 인코딩을 결정한다.
- vim의 termencoding: terminal로부터 전달받은 character들의 현재 인코딩. terminal의 인코딩을 vim에서 셋팅해주는게 아니라 단지 알려주는 역할을 할 뿐이다.
- vim에 쓰여지는 character의 byte값은 locale이 아니라 terminal의 encoding을 따른다.
2. vim 테스트
vim열고 안녕을 입력후 닫은 후 hexdump값을 본 뒤 다시 열어서 글자가 깨지는지 확인한다.
[상황1]terminal encoding: UTF8, vim enc: EUCKR, vim tenc, fenc = default
- 입력화면: 깨짐
- hexdump: EC 95 88 EB 88 95(UTF8)
- vim다시열면 enc, fenc가 utf8로 변경돼있고 글자가 제대로 보임.[상황2]terminal encoding: UTF8, vim enc: EUCKR, vim tenc=UTF8, fenc = default
- 입력화면: 잘보임
- hexdump: EC 95 88 EB 88 95(UTF8)
- vim다시열면 enc, fenc가 utf8로 변경돼있고 글자가 제대로 보임.[상황3]terminal encoding: UTF8, vim enc: EUCKR, vim tenc=EUCKR, fenc = default
- 입력화면: ????(물음표값이 입력됨)
- hexdump: 3f 3f 3f 3f (?의 아스키값)
- vim다시열면 enc, fenc가 utf8로 변경돼있고 글자는 여전히 ????로 보임.3. 결론
- 가능하면 vim의 enc와 terminal의 encoding이 동일해야 한다. 둘이 다를 경우 vim의 tenc를 terminal encoding값으로 셋팅해줘야 글자가 정상적으로 보인다. vim의 tenc와 실제 terminal인코딩이 다를경우 ?가 저장된다.